Εξόρυξη δεδομένων και συναισθηματική ανάλυση κειμένων
Στις 24 Φεβρουαρίου γίνεται εισβολή από στρατιωτικές δυνάμεις της Ρωσίας προς τα ανατολικά σύνορα της Ουκρανίας. Υποστηρίζεται πως η εισβολή αυτή αποτελεί μία έξαρση της ιστορικής συνέχειας του πολέμου μεταξύ Ρωσίας και Ουκρανίας που ξεκίνησε το 2014, και δημιούργησε μία από τις μεγαλύτερες κοινωνικές κρίσης όσον αφορά το προσφυγικό.
Το παρόν άρθρο, θα εστιάσει χρονικά από την εισβολή του Ρωσικού στρατού στην Ουκρανία στις 24 Φεβρουαρίου μέχρι και τις 2 Ιουλίου, και στην συνέχεια θα περιγράψει μεθόδους ανάλυσης του κειμένου τόσο στατιστικά όσο και γλωσσολογικά, με στόχο της κατανομή των κειμενων αυτό σε 3 κλάσεις που δηλώνουν πολικότητα. Η ανάλυση αυτή πραγματοποιείται τόσο σε γλωσσολογικό όσο και σε στατιστικό επίπεδο, με χρήση μοντέλων μηχανικής μάθησης και κλάσεις αλγορίθμων NLP (Natural Language Processing).
Για τις ανάγκες της έρευνας αυτής, απαραίτητη προϋπόθεση είναι η συλλογή δεδομένων που αναφέρονται στην εισβολή της Ουκρανίας. Ώς εκ τούτου, η επιλογή έγινε ανάμεσα από τρία μεγάλα ειδησεογραφικά πρακτορεία της ελλάδας, ΚΑΘΗΜΕΡΙΝΗ, ΝΑΥΤΕΜΠΟΡΙΚΗ, ΕΦΗΜΕΡΙΔΑ ΤΩΝ ΣΥΝΤΑΚΤΩΝ και ένα της Αγγλίας, THE GUARDIAN.
| Πηγή | Γλώσσα | Άρθρα | Σχόλια χρηστών |
| ΚΑΘΗΜΕΡΙΝΗ | el | 3230 | NaN |
| ΝΑΥΤΕΜΠΟΡΙΚΗ | el | 4628 | NaN |
| EFSYN | el | 2400 | NaN |
| THE GUARDIAN | en | 3205 | 67478 |
Η συλλογή των άρθρων έγινε ξεχωριστά για κάθε δημοσιογραφικό μέσο, καθώς χρειάστηκαν διαφορετικές τεχνικές εξόρυξης δεδομένων σε σχέση με την αρχιτεκτονική του κάθε ιστοτόπου. Το αποτέλεσμα της παραπάνω διαδικασίας είναι η δημιουργία μιας βάσης δεδομένων με 20 μεταβλητές και 13.463 συνολικά περιπτώσεις σε 2 γλώσσες, αγγλικά και ελληνικά.
Η υλοποίηση της βάσης έγινε με γλώσσα προγραμματισμού και βιβλιοθήκες Python. Ο πηγαίος κώδικας βρίσκεται στο Github εδώ.
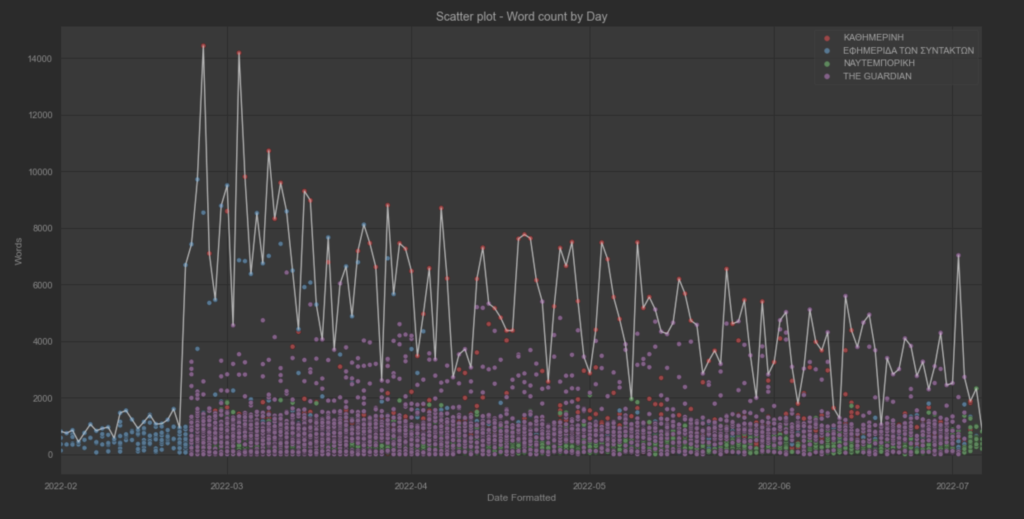
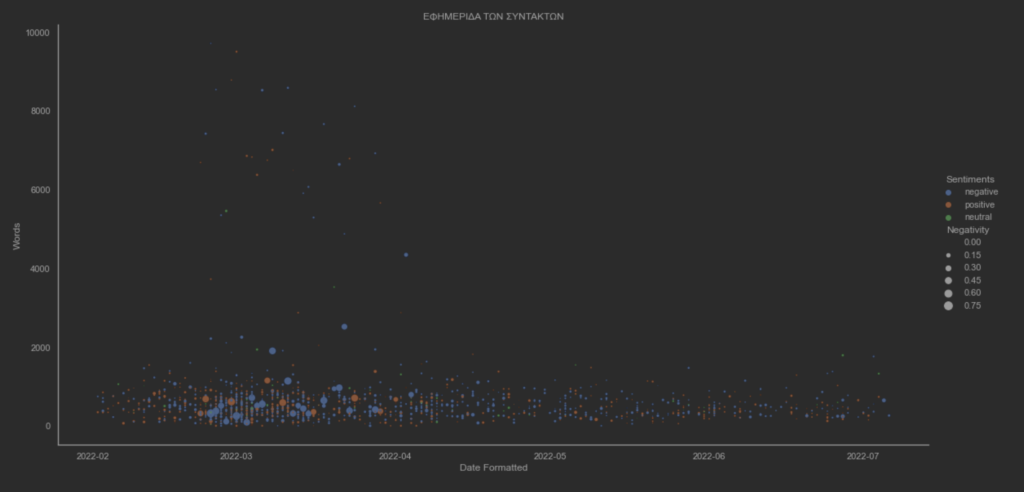
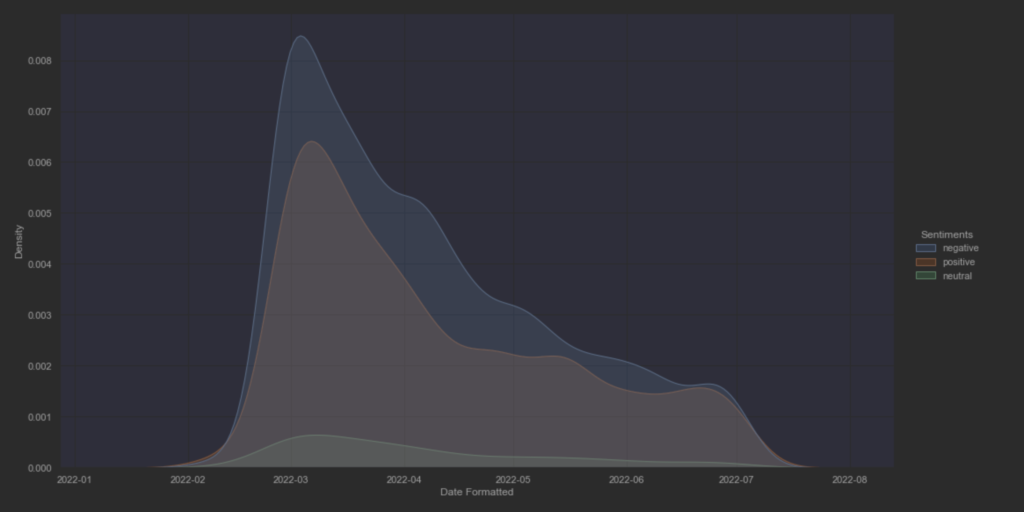
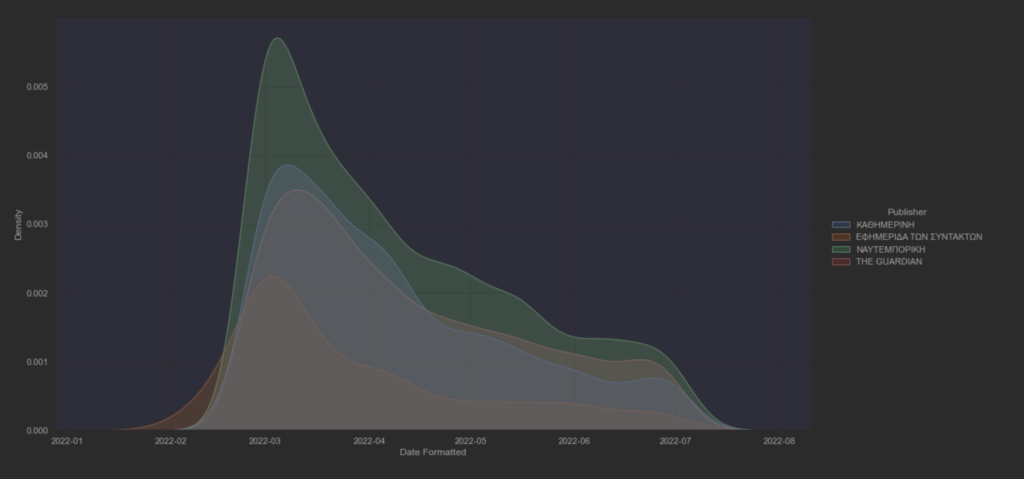
Φαίνεται πως η διακύμανση είναι καθοδική απο την έναρξη της εισβολής μέχρι και σήμερα, με κατα τόπους μικρές εκρήξεις το οποίο συνδέεται άμεσα με τα γεγονότα ανα μέρα. Συνολικά υπάρχει μία καθοδική πορεία από την αρχή της εισβολής.
NLP
Για κάθε ένα από τα άρθρα που συλλέχθηκαν έγινε γλωσσολογική ανάλυση και στα ελληνικά και στα αγγλικά.

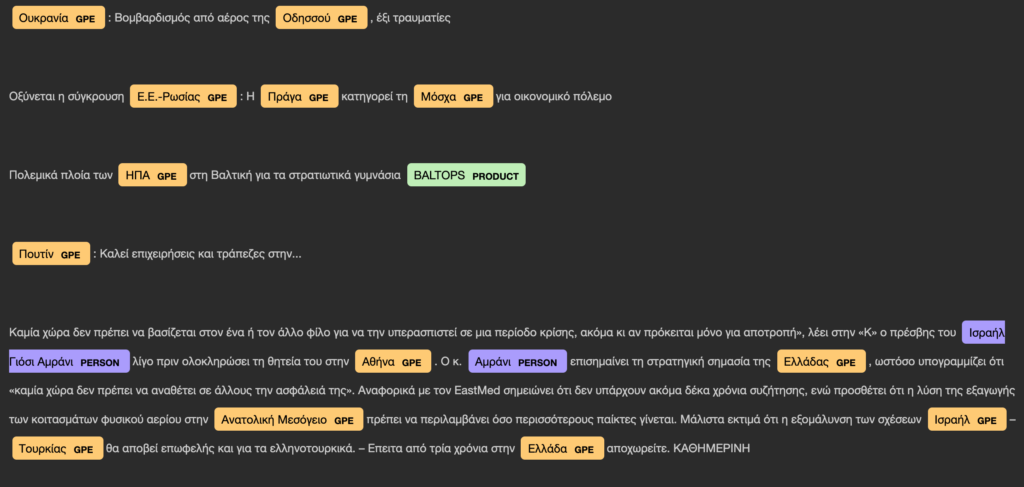
Ανάλυση κειμένου με την χρήση βιβλιοθήκες spaCy, αγγλικού λεξικού από το οποίο εξάγονται ποιοτικά χαρακτηριστικά λέξεων μέσα από προτάσεις. Συγκεκριμένα, γίνεται αναγνώρισης προσώπων, οργανισμών, χωρών, ημερομηνίας κλπ.
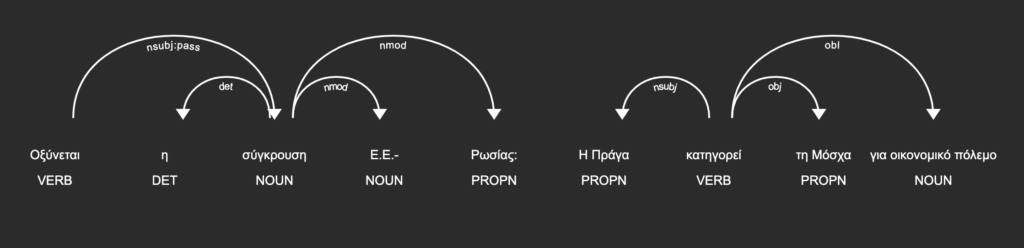
Επιπλέον, γίνεται εξαγωγή χαρακτηριστικών που αφορούν την δομή της γλώσσας και πιο συγκεκριμένα γίνεται αναγνώριση της σύνταξης της πρότασης σε κόμβους. Κάθε κόμβος αυτός είναι μέρος του λόγου, και δηλώνει την εξάρτηση που έχει στην πρόταση. Ένα παράδειγμα παρακάτω σε οπτική αναπαράσταση.
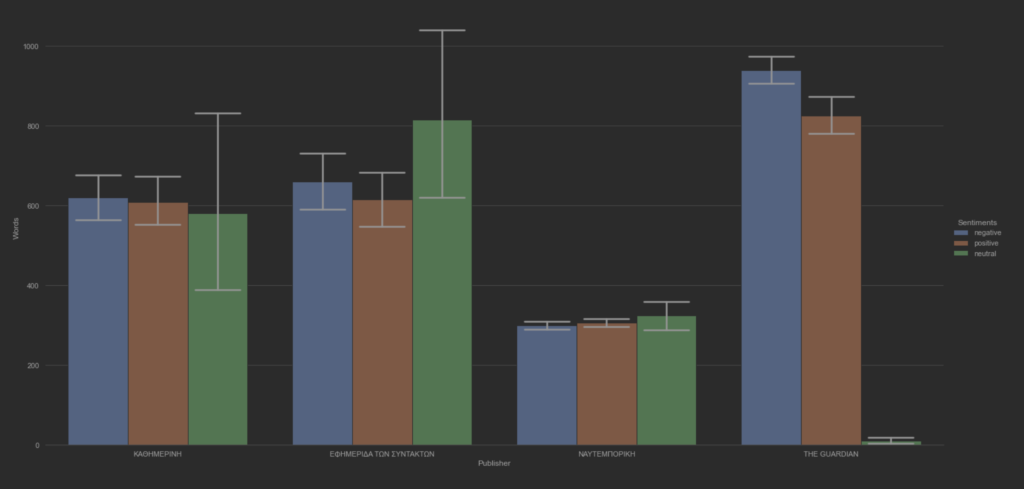
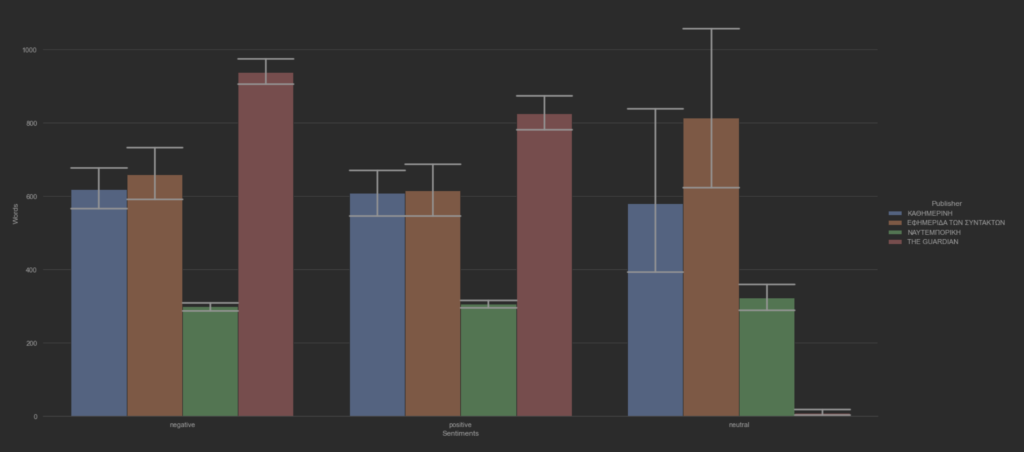
Κατανομή λέξεων ανά συχνότητα και ανά συναισθηματική βαρύτητα.
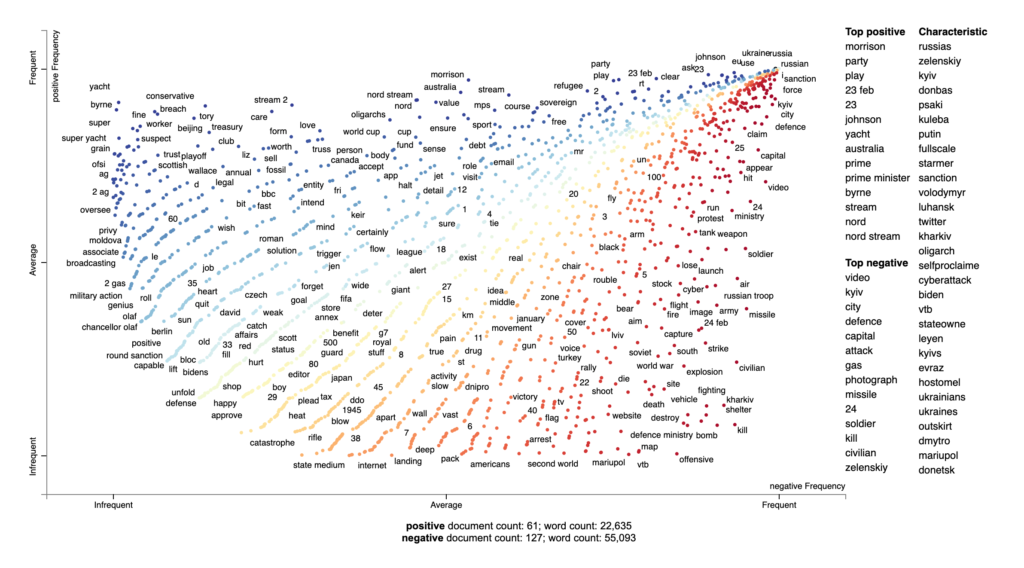
Sentiment Analysis
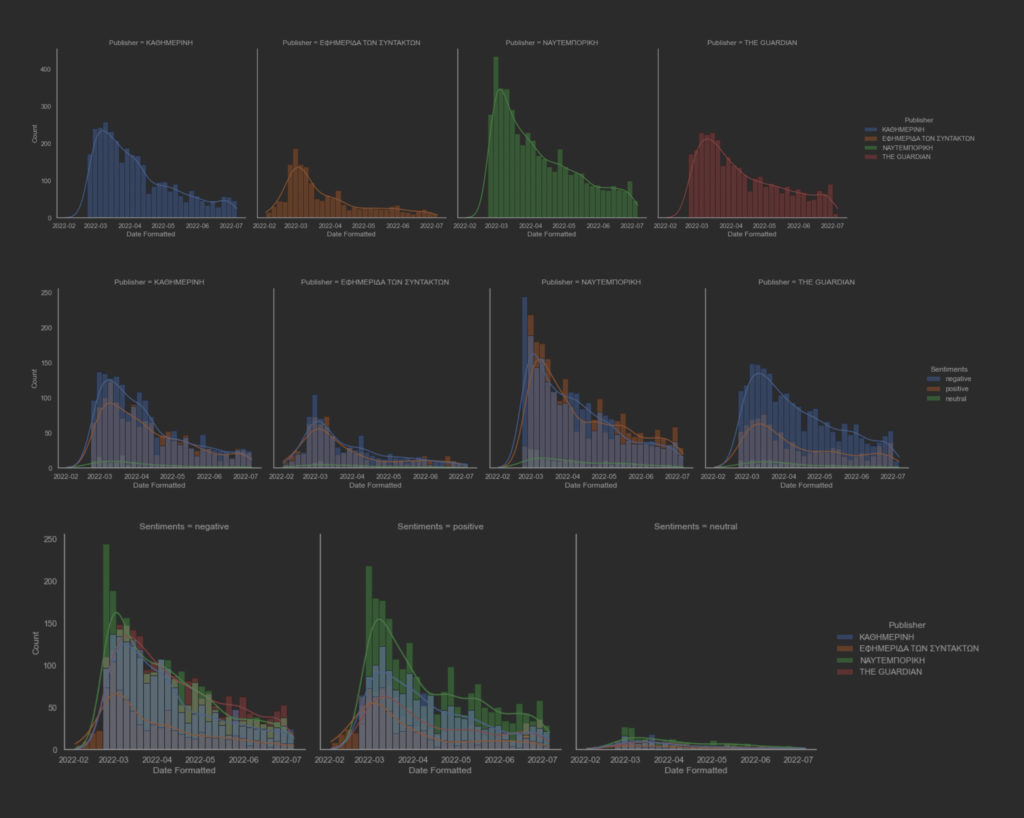
Στην συνέχεια, με την χρήση προκαθορισμένων λεξικών που φέρουν συναισθηματικά χαρακτηριστικά ανα λέξη και εκπαιδευμένων μοντέλων ταξινόμησης έγινε προσαρμογή 13463 άρθρων, στην αγγλική και ελληνική γλώσσα για τον χαρακτηρισμό των άρθρων αυτών σε Θετικά, ουδέτερα και αρνητικά. Αυτές είναι οι 3 κλάσεις που αναφέρονται παραπάνω στο άρθρο. Πριν της ταξινόμησης όμως έχουμε ανάθεση δεκαδικών τιμών, δηλαδή βαθμολογιών αξιολόγησης, οι οποίες είναι ήδη ταξινομημένες από τα εκπαιδευμένα μοντέλα. Έτσι, αν και εφόσον, υπάρξει ταίριασμα μία λέξης με αρνητική βαθμολογία, τότε η τιμή που θα γίνει ανάθεση θα υπολογιστεί σύμφωνα με την βαθμολογία του μοντέλου για την λέξη αυτή ανά την συχνότητα εμφάνισης αυτής. Ως εκ τούτου, δημιουργούνται 2 νέες μεταβλητές που παίρνουν τιμές από 0 μέχρι 1 και μετρούν την Θετικότητα και την Αρνητικότητα του άρθρου. Οι τιμές είναι κανονιστικές, έτσι ώστε να η βάση δεδομένων αυτή να χρησιμοποιηθεί με αλγόριθμους μηχανικής μάθησης στο μέλλον.
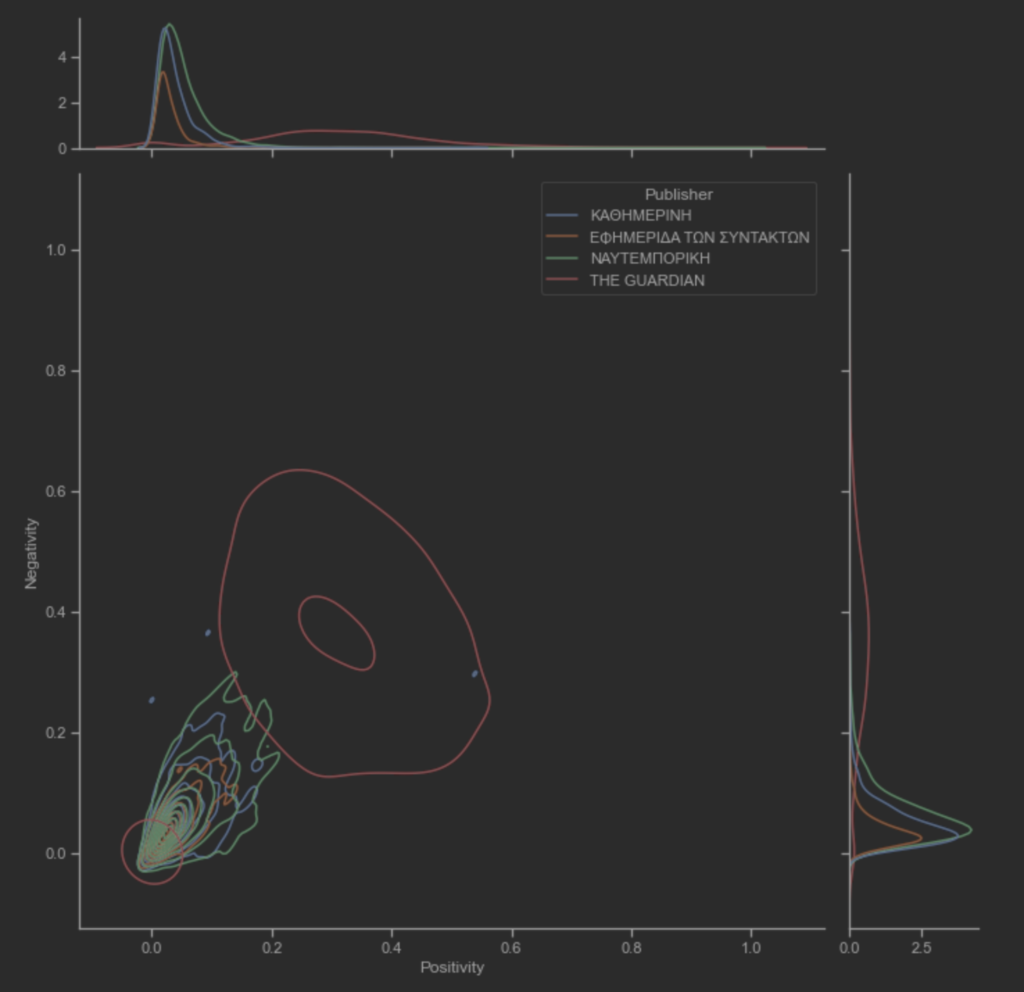
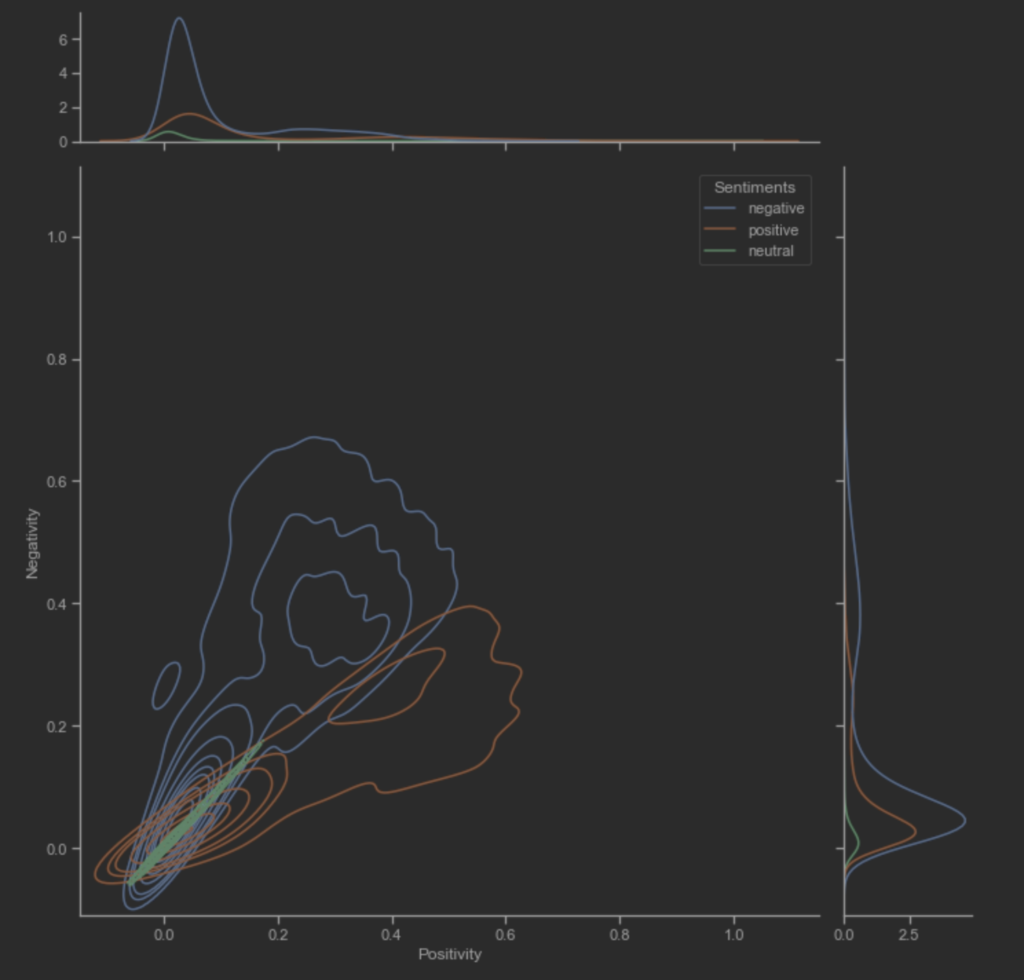
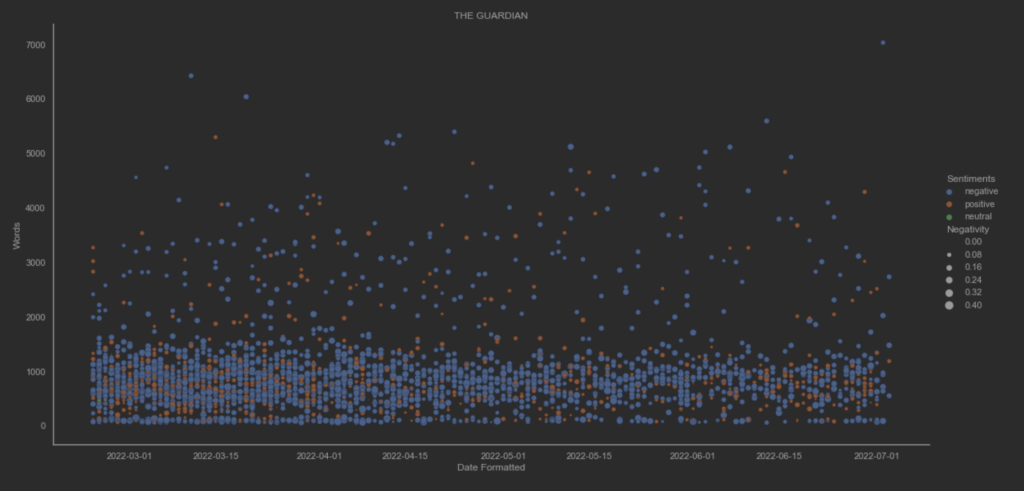
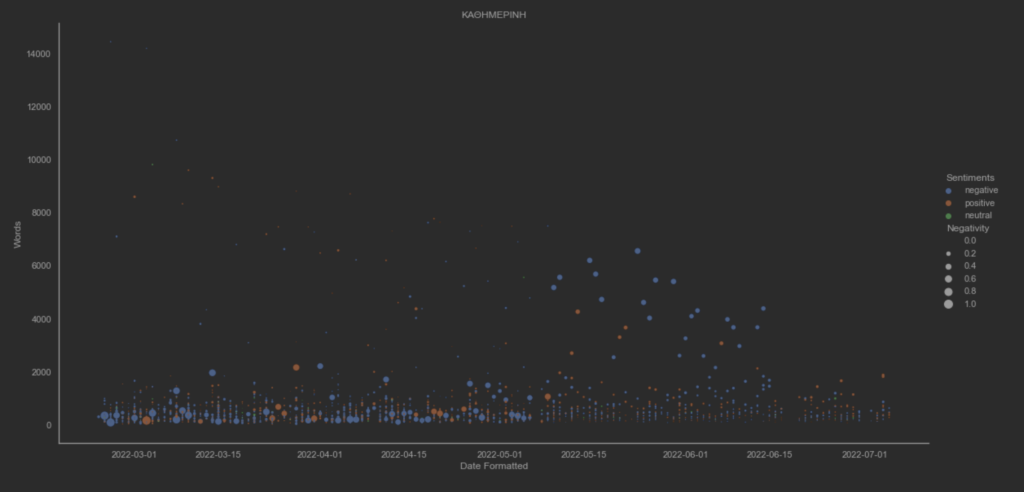
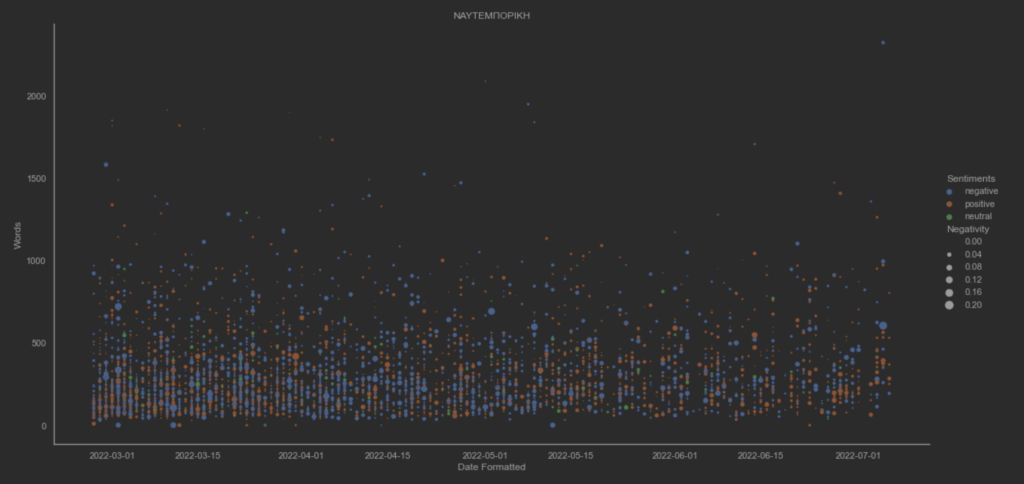
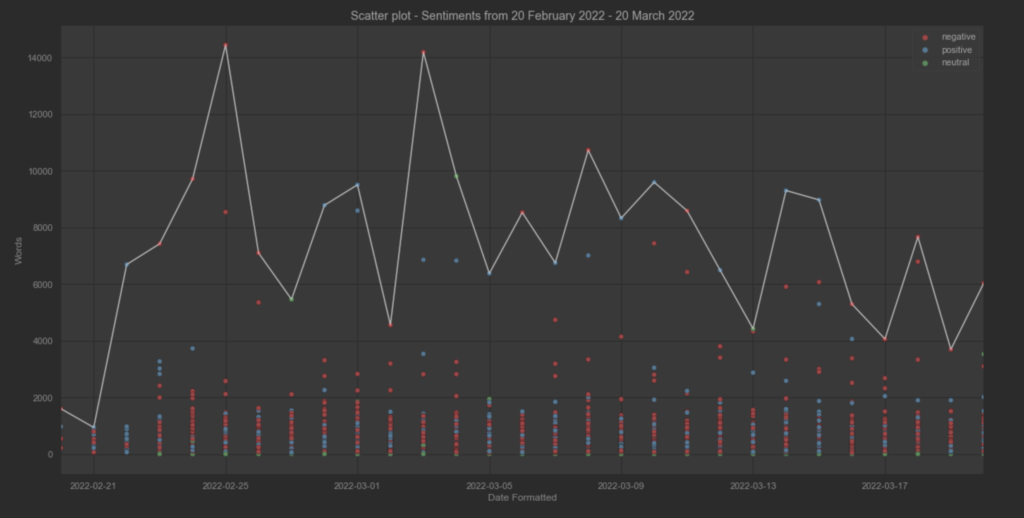
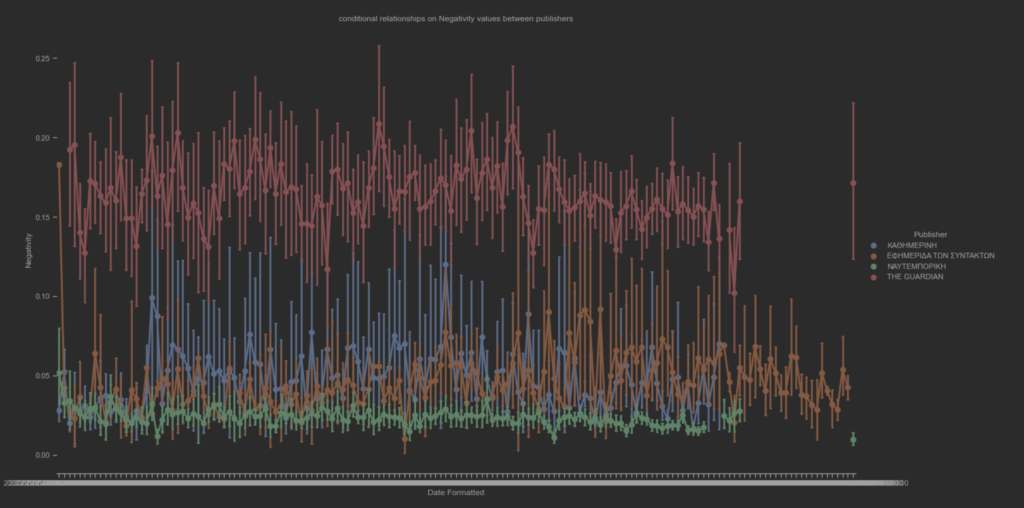
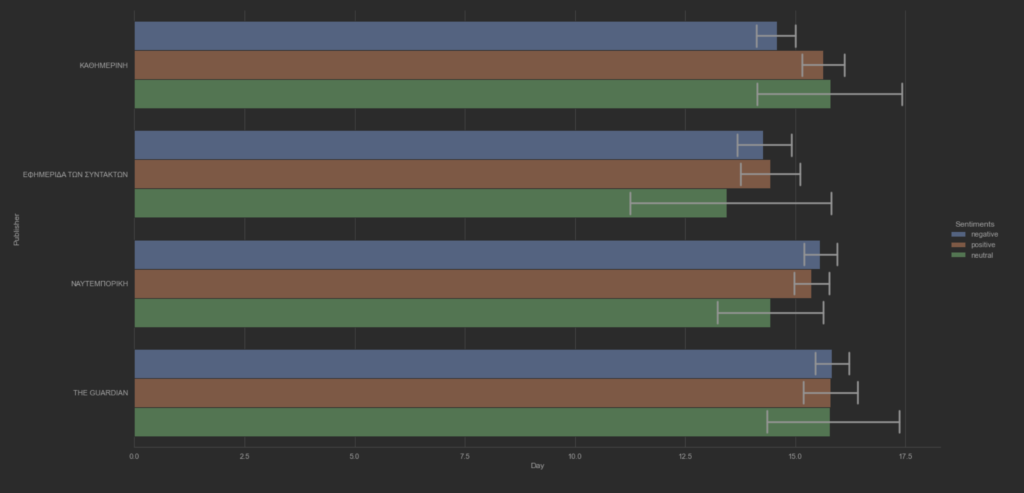
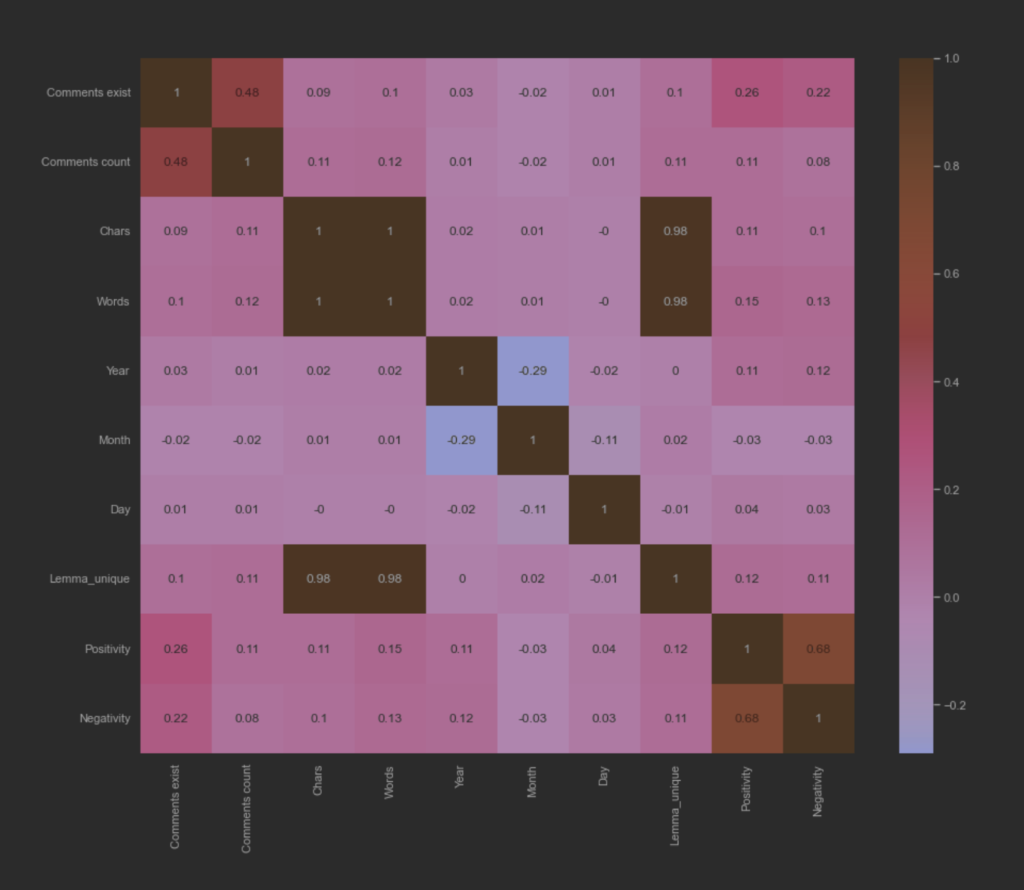
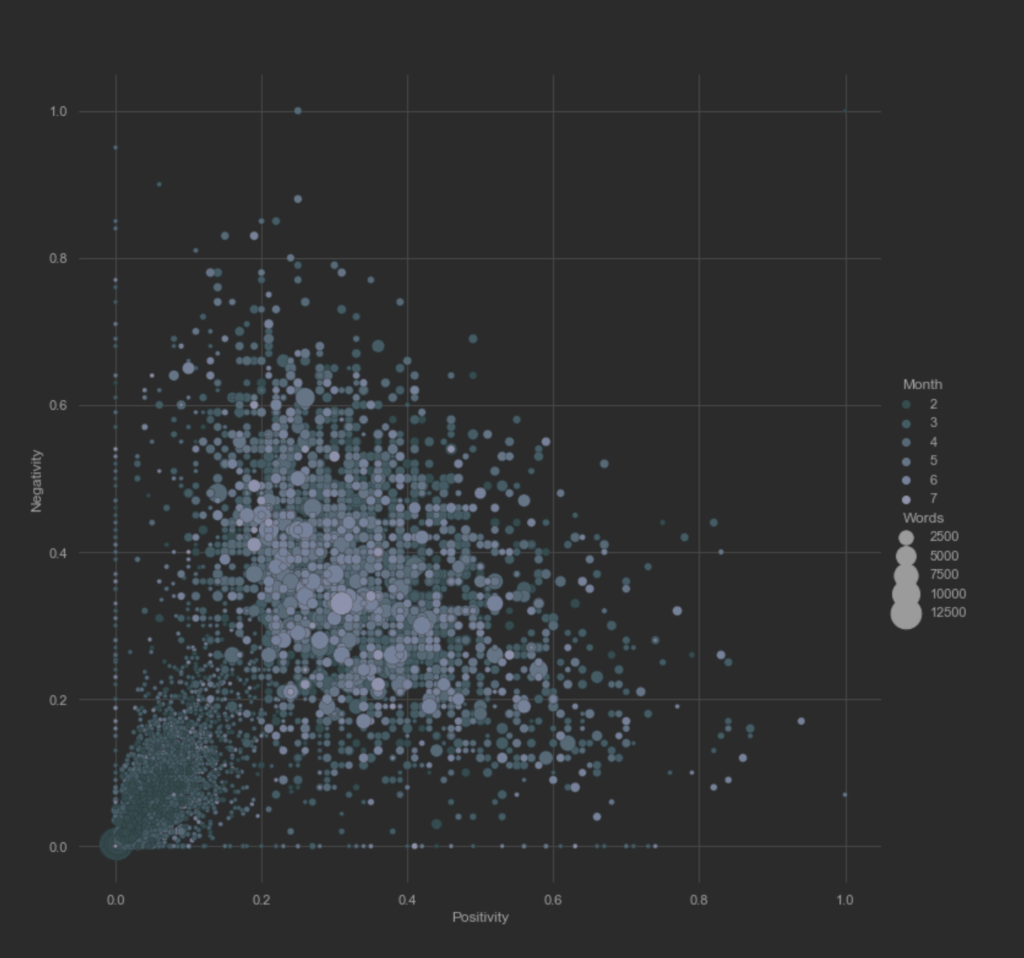
Ο υποθετικός συναισθηματικός συσχετισμός των άρθρων μεταξύ των ειδησεογραφικών πρακτορείων ανα ημέρα. Η διακύμανση του THE GUARDIAN φαίνεται να έχει μεγαλύτερες τιμές. Επίσης, η διαδικασία κανονικοποίησης των τιμών των μεταβλητών αρνητικότητας και θετικότητας δεν επηρέασε τις διακυμάνσεις τους.

Αντώνης Καλαγκάτσης